



At Rootly, we’re building the future of reliability by leveraging applied AI, and part of that mission is benchmarking LLMs. Today's public benchmarks are generally optimized for software engineering tasks, but very little is done to assess models for SRE tasks. That’s why the lab is designing a benchmark to test against tasks that reliability teams must tackle.
As Mistral dropped its new series of Magistral models, we saw an opportunity to put them – and the rest of the field – to the test. We iterated on our past research and built a new benchmark suite. Here is what we found.
Topline Results
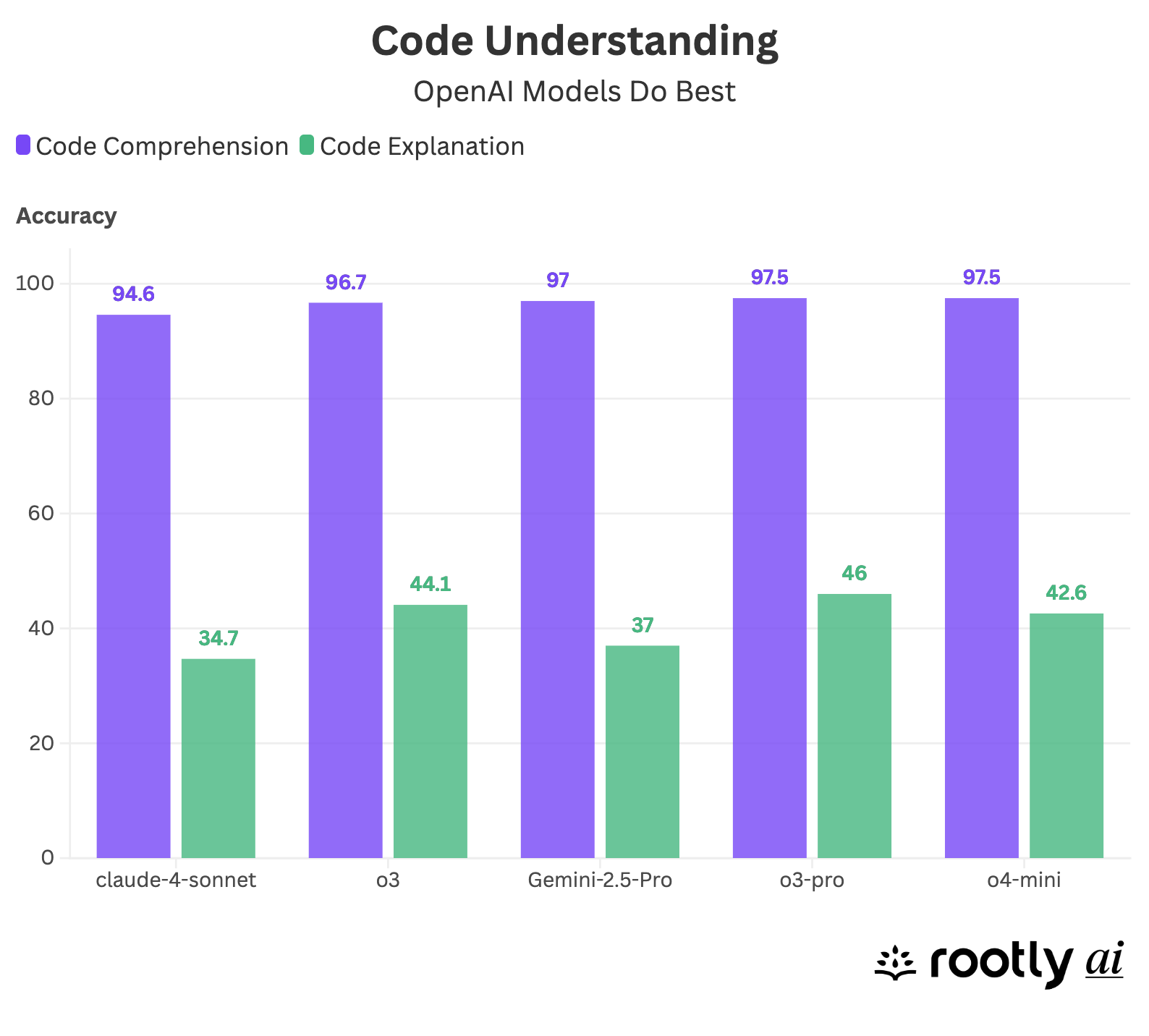
Code Understanding
Let’s jump straight into the results, starting with code understanding, a key skill for SREs when they're in the middle of an incident and need to debug a codebase they may have never touched before. As found in our previous benchmark, OpenAI’s o3, o3-pro, and o4-mini were consistently top performers. Gemini-2.5-pro matched their performance on the GMCQ test (code comprehension) but fell behind on the Reverse QA task (code explanation).
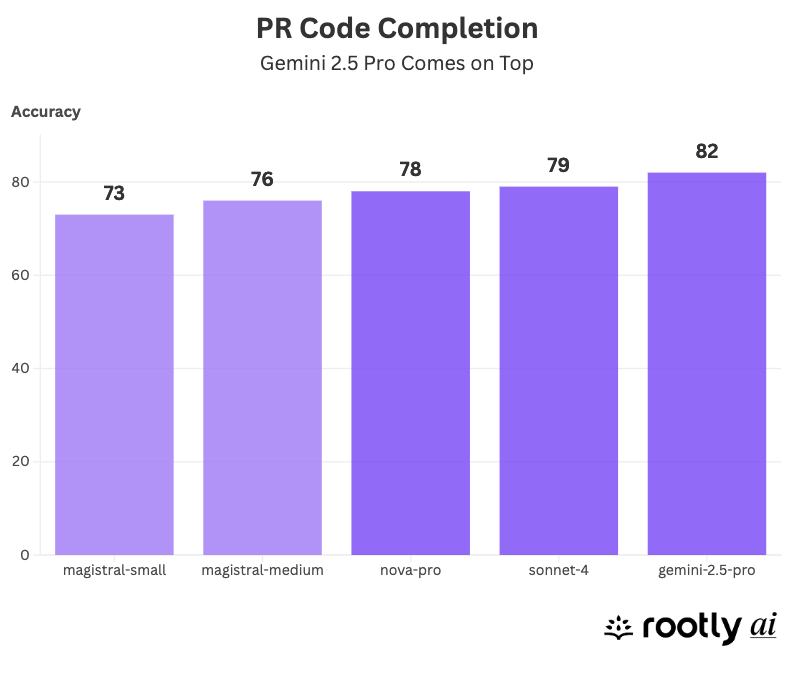
Code Completion
But in code generation (MPR Gen), Gemini-2.5-pro took the lead, followed by Anthropic’s Claude-4-sonnet and Amazon’s Nova-pro. This highlights a key insight: no single model dominates across all tasks – you have to choose based on the use case.
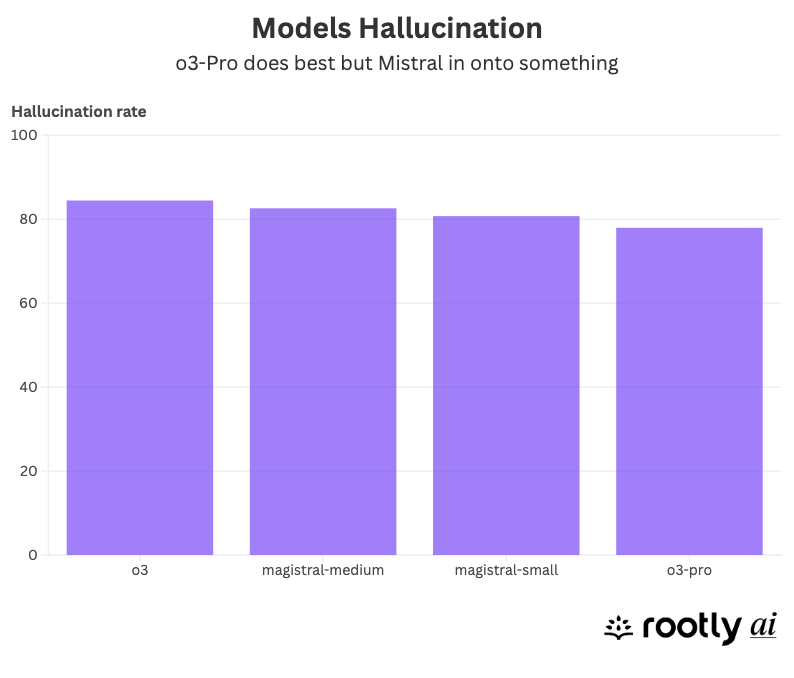
Hallucination Resistance
An SRE has very low tolerance for hallucinations when relying on AI, which is why we constructed high expectations when calculating this index. In our test, every model performed poorly, with hallucination rates exceeding 80% across the board. While o3-pro came out on top, Mistral was the real surprise. Despite weaker accuracy on other tasks, its Magistral-small and Magistral-medium variants hallucinated significantly less than expected. Hallucinations pose a significant barrier to the reliable use of LLMs in production. Mistral may be onto something here.
Models Price: a Wide Range
To gain a better understanding of the overall model performance, we calculated an average for each model and converted it into a score.
By reducing o3 prices by 80%, OpenAI makes waves with a price tag at $8 per million tokens. That’s great value, especially since o3 was a top performer across multiple tasks. Conversely, o3-pro clocks in at $80/million – 10x the price, with no 10x performance to justify it. Mistral-small also earns an honorable mention for hallucination resistance at the lowest cost.
Methodology
We designed four tasks based on real-world code pulled from GitHub to simulate what SREs actually do daily.
The first is GMCQ (GitHub Multiple Choice Questions). In this task, the model is given a bug report, pull request title, and a description. It must choose the correct code patch from four options – the one that resolved the issue. This test simulates fast incident triage, where SREs often work with limited context.
Next is Reverse QA, in which the model receives a code patch and must write a clear, human-readable pull request title and description. This evaluates the model’s ability to explain code changes, an essential skill for postmortems and cross-functional communication.
The third task, MPR Gen (Masked Pull Request Generation), focuses on code generation. Given a PR title, description, and partially masked code, the model must fill in the missing section. It mimics the kind of rapid “hotfix” patching SREs are often required to do during high-pressure situations.
Finally, we have QA Halu, which measures hallucination resistance. Here, the model is asked to summarize a pull request. If the output includes any information not in the original PR, it's marked as a hallucination. This task is critical; models that invent details can’t be trusted in reliability workflows.
If you’re interested in exploring the benchmark code or using it yourself, you can find it on the Rootly AI Labs GitHub page.
The Best Models for SRE
Ultimately, model choice depends on your specific use case. Performance varies across tasks, and price often matters just as much as accuracy. For high-volume, low-stakes workflows – like filtering and triaging monitoring alerts – you might prioritize speed and cost efficiency. But for critical tasks like root cause analysis, it’s worth investing in a more capable, higher-precision model. If I had to pick, I’d go with o3 and Gemini-2.5-pro for their strong performance-to-cost ratio.
If you're interested in redefining what reliability engineering looks like in the age of AI, consider joining Rootly AI Labs. We collaborate with top talent – including the Head of Platform Engineering at Venmo and the former Director of AI at Twilio – and Anthropic, Google Cloud, and DeepMind back us. We're always looking for new fellows to help push the boundaries – get in touch!